Note
SOAR
Using AlloyDB for PostgreSQL, I became interested in the underlying algorithm, based on ScaNN and recently extended with SOAR.
During indexing, a structure is built to organize vectors in space, so that search is performed only on a subset. Vectors are quantized and assigned to different partitions via SOAR. Let’s analyze this.
I have data in a vector database and a query . I want to return the closest vectors to . A linear scan gives exact results but is inefficient (intractable) due to the curse of dimensionality.
We approximate accuracy to gain efficiency, hence Approximate Nearest Neighbor.
Spill Tree
Data replication to reduce partitioning errors.
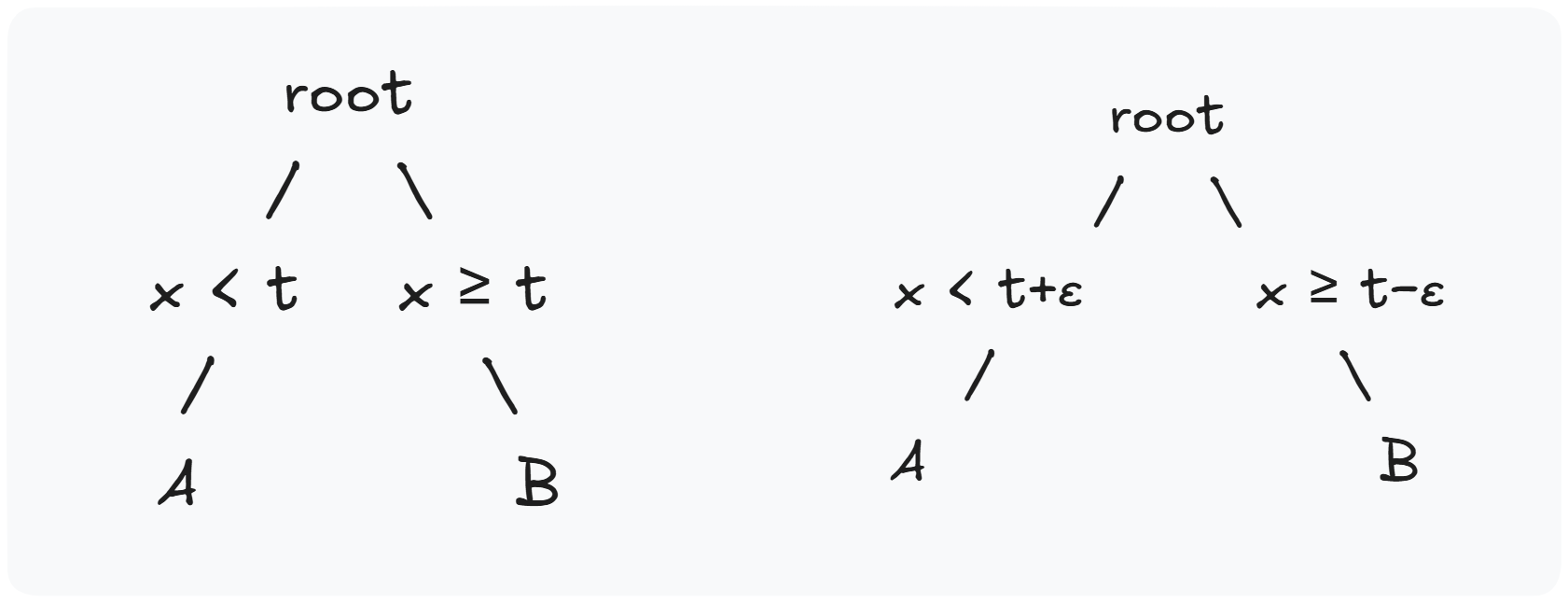
Here, is a separating hyperplane that divides the space into two regions. An overlap is introduced so that points near the boundary are replicated in both and .
However, the complexity is exponential: if at each level of the tree a point falls into the overlap region, it is duplicated in both children and appears times.
Vector Quantization
We approximate vector values with centroids. This process returns two objects: codebook and assignment function.
C \in \mathbb{R}^{c\times d} \tag{1}
is a matrix with rows, each a vector in , so each row is a centroid.
\pi(v):\mathbb{R}^d \mapsto \{1,\dots, c\} \tag{2}
The assignment function ensures each vector is mapped to the nearest centroid. At query time, we compute the inner product between and all centroids, rank them by score, and retrieve points from those partitions.
This is not free: replacing with its centroid introduces error.
Residual
What we lose by replacing with its centroid.
If the residual is large and positive, the centroid underestimates the true score, and the correct partition may not be visited.
This happens when the residual is aligned with the query , since the error is:
A high makes the point harder to retrieve.[^soar-paper]
Spilling with Orthogonality-Amplified Residuals
To avoid losing a point during search, we assign it to multiple partitions. But how do we choose the additional one?
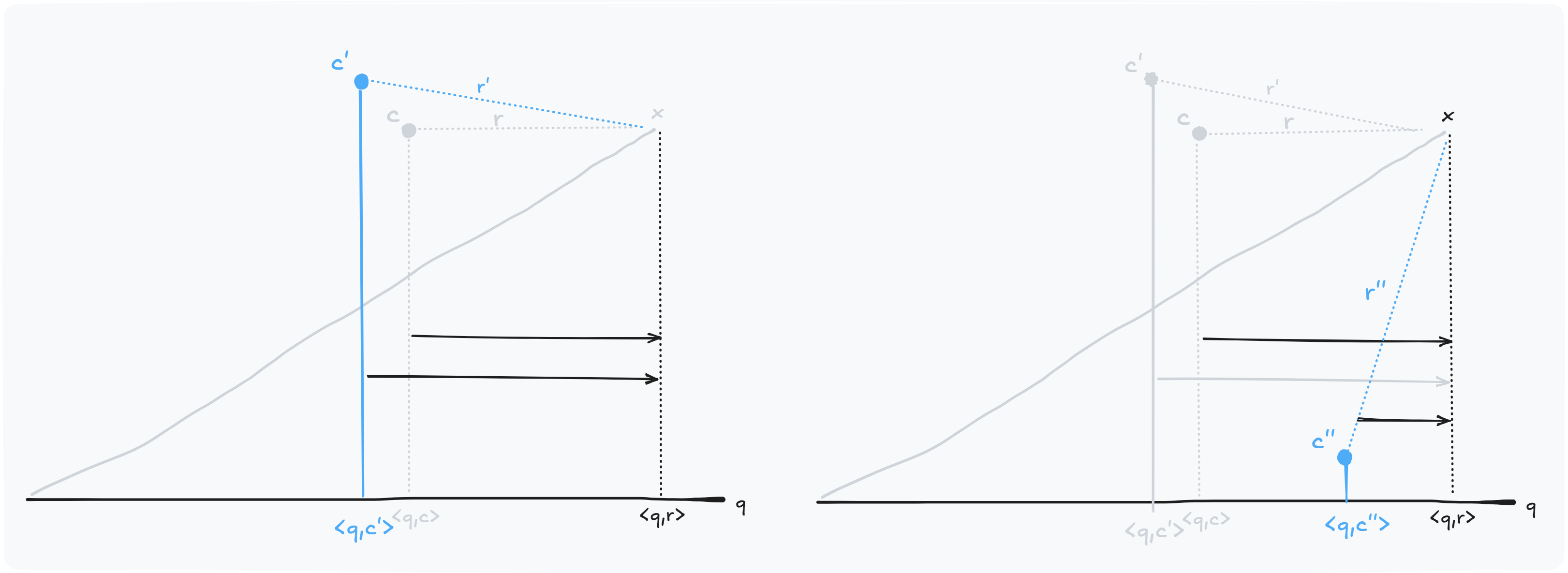
On the left, choosing produces a new residual similar to .
On the right, choosing produces a residual almost orthogonal to .
This is crucial: if two residuals have similar direction, they fail in the same cases. If they are orthogonal, at least one will give a good score.
Thus, we choose the centroid using a loss that minimizes quantization error while penalizing alignment between residuals:
where:
- is the residual of the first assignment
- is the candidate residual
- is a query 1
- is the angle between and
- gives more weight to cases where the original error is high, i.e. when is aligned with
This loss explicitly reduces correlation between errors and , which is the core idea of SOAR.[^soar-paper]
All these multiple assignments increase memory and indexing cost linearly with the number of copies per point. It is shown that a second assignment is already sufficient to cover most cases; additional ones bring marginal benefits relative to the cost.
Link to the official paper: https://arxiv.org/pdf/2404.00774
Footnotes
-
can be seen as a representative sample of real queries, i.e. the distribution of queries expected during system usage ↩